
Using Computer Vision and AI to monitor berry, fruit and vegetable size and quality: FAST/zh

内容
基于立体相机和关键点检测的蔬菜尺寸测量[1]
本文旨在 1)蔬菜识别和 2)尺寸检测
使用双目立体相机,可获得 1) 彩色图像和 2) 深度图
可对黄瓜、茄子、番茄、辣椒进行分类(每个对象定位6个点),此方法可对60cm以内的四种常见蔬菜进行分类,并准确估算其直径和长度。
基于边缘检测的测量可以简要描述尺寸,但无法计算形状复杂的水果的长度。
为了解决距离减小的问题,他们将 RGB 图像上临界点的像素距离投影到 3D 空间中。
数据准备:
· 我正在用 1600 张图像标记 COCO 数据集中的标准日常物体,以训练关键点。
· 他们使用 RealSense 深度相机获取事物的 RGB 图像和深度图。
预先训练的基于关键点区域的 CNN 对蔬菜进行分类,并在多个尺度上定位它们。-> 通过计算关键点之间的距离来估计蔬菜的大小。Dectron2 平台识别蔬菜的类型并找到六个关键点(花梗、顶部、左侧、底部、右侧和中心)
获取RGB图像和深度图:
开始 > 设置图像大小为 640 x 480 > 获取 RGB 帧和深度帧 > 将深度帧与 RGB 帧对齐 > 填充深度帧 > 输出 RGB 图像和深度图像 > 结束。
蔬菜大小估算
输出:RGB 图像上关键点的像素坐标 (x,y)。深度图提供了生命能量与相机之间的距离。
左右关键点用于估算直径,上下关键点用于测量长度,中心关键点用于计算深度,花梗关键点为自动采摘预留的采摘点。
计算3D空间中距离的方法:
· 通过将关键点投影到三维空间中来计算关键点的三维空间坐标。然后使用三维坐标直接计算两点之间的距离。(理论上,这种方法可以给出更准确的距离,但会丢失物体边缘的深度)
· 计算RGB图像中两点之间的像素距离d,并将像素距离映射到三维空间中,同时用数学方法修正不同关键点之间的深度差异引起的距离误差。结果
- 蔬菜分类
当深度小于80 cm时,四种蔬菜的正确率很高,接近100%;当深度大于80 cm时,随着深度的增加,成功率逐渐降低,黄瓜和茄子的成功率下降得更快。
- 尺寸估算
分别对这些蔬菜的直径和长度进行了 MAPE 估计。
**这种方法需要高端相机,所以它不是我们的首要任务。
使用 K 均值聚类和 SVM 进行蔬菜病害检测 [2]
蔬菜取决于它们的特征,即颜色、形状、大小和质地。通过提取这些特征,可以利用算法来区分蔬菜。K 均值聚类算法可以通过接收 2D 图像作为输入,将受感染的蔬菜与非异常蔬菜分开来检测受感染的蔬菜。这可以分为三个步骤:
· 增强:图片被调整为 250 x 250 像素,以降低其阴影指数。对比度增强可改善阴影边缘。
· 分割(K均值聚类):聚类算法从蔬菜中分割出不自然的部分。
· 分类(SVM):我们可以通过提取特征对蔬菜进行分类。
蔬菜的识别取决于其特征。这些特征包括颜色、形状、大小和纹理。我们利用算法提取这些特征来区分蔬菜。
蔬菜病害检测
拍摄高质量图像 > 去除噪声(直方图均衡化 > 图像分割(k均值聚类将图像从RGB转换为CIELAB系统)> 根据k均值聚类的结果标记每幅图像 > 特征提取 > 用SVM进行分类 > 识别是否被感染。
预处理:它从蔬菜图像中去除不需要的噪音。它还对图像执行直方图均衡化以分配强度,从而提高图片质量。用于预处理的技术是过滤图像、cron 图像和调整图像大小。
分割:将图像分成许多有意义的部分。可以通过 k 均值聚类、otsu 阈值、分水岭等方法完成;我们将图像从 CIERGB 分割到 CIELAB。K 均值聚类应用于具有 3 个聚类的 L*a*b* 图像。
准确度 =(正确输出数/尝试图像总数)x 100
K 均值聚类算法
定义聚类数 > 选择质心 > 根据强度值与强度值的距离对图像点进行聚类
计算机视觉在水果蔬菜外部品质检测中的原理、发展及应用:综述 [3]
使用传统的计算机视觉系统(RGB)无法检测不明显的缺陷。典型的光谱图像由与特定波长相对应的单色图像组成。与传统计算机视觉甚至人类视觉相比,高光谱和多光谱计算机视觉系统具有天然优势。在检查瘀伤或腐烂时,最有效的波长可能非常不同。有效波长通常可以从原始光谱、预处理光谱或一些多元分析(模式识别)技术中选择。
原始光谱中出现峰或谷的波长位置可能就是最有效的波长。直接根据原始光谱确定有效波长是选择有效波长的最简单方法。然而,由于存在噪声和基线漂移,在某些检测情况下,峰和谷并不总是有效的。因此,在根据峰和谷选择有效波长之前,光谱预处理始终是必不可少的。
主成分分析(PCA)、独立成分分析(ICA)、最小噪声分数(MNF)、偏最小二乘(PLS)、线性判别分析(LDA)、逐步判别分析(SDA)和人工神经网络(ANN)是高光谱图像分析、降维和有效波长选择中最常用的多元分析方法。
利用计算机视觉评价水果蔬菜品质:综述 [4]
预处理
增强图像数据,克服难以克服的失真并扩大图像数据的特征。食品质量评估中使用的图像预处理方法是像素预处理和局部预处理。
· 像素预处理:将输入图像转换为输出图像,使得每个输出像素与具有相应坐标的输入像素相关。
· 局部预处理(过滤):使用输入图像中像素的一个小邻域在输出图像中产生新的亮度值”。它使用简单滤波器(降低噪声)、中值滤波器(降低峰值噪声)和改进的无形滤波器(识别鸡蛋中的裂缝)。
分割
主要功能是在客观评估期间分离背景以处理重要区域。正确的分割对于图像分析的进一步发展至关重要;不正确的分割会降低分类器的性能。最常见的分割方法是阈值和聚类。硬聚类是一种简单的技术,它根据属于相同簇的像素对图像进行分割。硬聚类的一个例子是 k 均值,其中评估与中心的距离,然后将每个像素分配给最近的中心。
特征提取
· 颜色特征:它是质量的间接衡量标准。颜色特征具有许多优点,例如效率高、易于从图像中提取颜色信息、大小和方向独立、能够表示图片的视觉内容、对背景复杂性具有鲁棒性以及能够将图像彼此分离。许多研究人员引入了各种颜色特征,包括颜色相关图、颜色相干向量、颜色矩、颜色直方图等。其中,颜色矩简单有效。最常见的矩是均值、标准差和偏度。由于 RGB 与人眼的视觉检查呈非线性,因此它无法分析食品的感官特性。CIELAB 颜色空间将所有颜色清楚地表征给人眼。它旨在提供一个与设备相关的模型作为参考,其中“L”是亮度的度量,“a”和“b”分别改变红/绿和绿/蓝平衡。它是感知均匀的,因此人类感知的颜色差异与 CIELAB 空间中的欧几里得距离相同。由于计算机视觉测量的颜色可以很容易地用从CIELAB颜色空间获得的染料进行分析,因此它为评估测量物体颜色的性能提供了一种可行的方法。
· 形态特征:两个相邻像素的距离导致特征提取。无论形状或方向如何,一旦分割了物体,面积和周长都是稳定且有效的。为了量化尺寸,使用长度和宽度。食品的形状通常在加工过程中发生变化。因此,需要及时恢复计算长度和宽度的方向。通过每两个边界像素的距离获得的穿过物体的最长线是重要轴。形状描述符的两类是 1) 基于区域(基于物体的积分面积)和 2) 基于轮廓(使用局部特征分割边界)。为了对草莓、柠檬和柑橘进行分类,使用直径(最小最大直径)。
使用 PCA 和人工神经网络识别苹果表面缺陷 [5]
使用人工 NN 和 PCA 检测“近红外”图像中的表面缺陷。神经网络在 PCA 集上进行训练和测试。PCA 成分来自两种波长的苹果图像的像素列。最后,该方法可以在包含 185 个缺陷的测试集中检测到 79% 的缺陷。
某些波段适合检测“苹果”的表面缺陷。
· 540 nm 对起泡点的缺陷分割效果最好。
· 750 nm 最适合用于治疗苦痘病、化学损害、木栓化、开裂、蝇斑病、冰雹损害、卷叶病、腐烂病、疮痂病和煤污病。
· 950 nm 是检测瘀伤、穿刺伤和烫伤的最佳波长。
PCA:用于数据缩减。
NN:用于分类问题。
阴影、表面不规则以及苹果的边缘也会呈现出较暗的色调,因此很难使用基于灰度值的简单分割来识别缺陷。-> 基于缺陷和无缺陷表面示例的 NN 可以合理地分离这两组。
创建NN的步骤:
- 图像被视为一个矩阵,其中的列代表样本,各个像素值是变量。
- 根据列是否包含缺陷,将其分为两类。
- 可以通过 PCA 对整个数据矩阵进行数据缩减,然后可以使用最重要的 PC 来训练 NN。
主成分分析将原始数据转换为新的数据空间,由一组新轴定义,通常称为特征向量。在这个空间中,第一个轴表示原始数据集中的最大变化,第二个轴表示下一个最大变化量,依此类推。请注意,在 Python 中,重要的特征向量从最后一个轴开始。
在 PCA 中,像素列被一列 PC 取代。优点:PC 的数量远低于像素数量,并且 PC 为分类提供了优化的基础。如果每列 PC 不代表缺陷,则分配一个值“零”,如果代表缺陷,则分配一个值“一”。此矩阵用于训练3 层网络:
- 第一层:Sigmoid
- 第 2 层:Sigmoid
- 第 3 层:线性
它不是前馈的。反向传播用于训练“Fletcher-Reeves”更新共轭梯度算法。标记训练集是半手动完成的。
理想的情况是使用“原始”图像,即直接从相机拍摄的图像。但这样做似乎是不可能的。因此,需要分步处理图像。
- 去除背景:将图像转换为灰度图像 > 确定阈值 > 显示水果的位置 > 确定每个像素值是否为背景 > 接下来调整列的大小 ---> 这样可以显著提高性能
- 图像框架缩小至苹果表面 60 度
- 过滤图像:为了限制导致误报的细微表面不规则性,使用 3x3 矩阵的“维纳”对图像进行过滤。维纳滤波器是一种线性滤波器,可根据局部图像方差自适应图像。方差较大时,滤波器的平滑处理较少。方差较小时,平滑处理较多。这种方法确保了由于瑕疵和擦伤造成的暗斑在过滤后不会发生变化,但细微不规则性会减少。
增材制造中的合成到真实复合语义分割 [6]
创建合成图像数据集
Thingiverse上的 CAD 文件构成了生成合成图像数据库的基础 > 上一步中的 STL 文件将转换为 G 代码 > 存储库的功能组件用作将 G 代码文件导入图形引擎的基础。为了创建逼真的渲染,在 Blender 中创建了类似于真实物理环境的场景。相机的位置以及照明程度和光源的位置都经过精心选择,以与实际工作空间紧密匹配。
基于 Mask R-CNN 的草莓病害实例分割模型 [7]
经典 vc。基于深度学习的方法:传统算法无法消除场景变化的影响。然而,基于深度学习的方法与传统方法相比,准确率更高,但由于训练时间较长,计算成本更高。
检测:旨在预测图片中物体的类别信息。物体检测在输入图像的捕获方向和距离方面提供了更大的灵活性。
分割:与分类或检测网络相比,分割模型产生的预测更加细粒度。
数据集:数据集由在真实田野而非实验室中收集的图像组成。因此,它引入了多个挑战,例如背景变化、复杂的田野条件、不同的照明设置等。因此,这些变化使我们设计的模型具有更高的能力,更加稳健和可推广。它包含 2500 张用手机收集的草莓病害图像。这些疾病经过专家验证。数据集由七种不同类型的草莓病害组成,图像涵盖了疾病的初期、中期和末期。数据集分为 1450、307 和 743 张图像,分别用于训练、验证和测试集。
使用图像处理技术和机器学习对水果和蔬菜进行品质分级:综述 [8]
图像处理在水果蔬菜分析中的应用:综述 [9]
本篇论文试图解决超市中根据水果的颜色、质地等自动寻找采摘水果的问题。
输入图像:图像中随机放置任意数量的单一品种的水果或蔬菜。塑料袋中的物体可能会改变色调,其反射也会发生变化。因此,系统应该能够使用更少的训练数据达到更高的准确率。
形成特征向量:裁剪 > 调整大小 > 提取HSV的色调和饱和度通道的平均值和范围
蔬菜品质通常以“颜色”、“形状”、“质量”、“硬度”、“大小”和“无伤痕”来衡量。西红柿和柠檬的分类基于其大小和颜色。
系统首先获取一个红桃区域的图像>匹配扩展识别整个区域>通过轮廓上直线垂直平分线的交点来测量拟合圆的潜在中心点>通过潜在中心点的统计参数来测量中心点&果实的半径。
自动视觉水果检测,用于收获量估算和机器人采摘 [10]
- 除了面部/行人检测等传统应用之外,对象分类还可以发挥其他用途。
- 2D 图像分割通过使用热像仪添加了额外信息。[11] >> 后果:计算复杂 > 耗时
- 热成像在准确性方面可能存在问题 -> 不能成为通用模型(水果不会直接暴露在阳光下)
- 本文目标:2D信息足以进行物体检测或定位。
- 在单个图像中定位水果 > 从多个图像中汇总估计值(需要多个视图)
数据集
- 正面训练:包含草莓的不同表示(例如不同的照明条件、不同的方向、被树枝和树叶部分遮挡、不同的视点......)
- 负向训练:移除物体。剩余的图像像素用作背景信息,保留特定应用的背景知识。
- 相机:两台 AVT Manta 相机,分辨率均为 1292 964 像素。
- 250 张训练图像、750 张测试图像、1500 张带标签的训练图像。(35 x 38)
目标:根据场景的 RGB 颜色输入图像提供所有成熟草莓的位置。
方法
- 使用 AdaBoost 构建级联分类器模型(它忽略颜色信息,通过比较灰度图像中的像素强度区域来关注梯度信息)
- 首先建立一个包含成熟和未成熟的草莓的模型,以便将草莓与背景分开。
- 第二个模型使用未成熟的草莓作为底片。
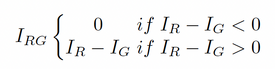
- 该方程支持红色区域,但忽略了绿色区域。
- 颜色变换可以帮助检测草莓的成熟度(如果检测到的像素中有超过 50% 表示成熟)> 与预处理过滤器相比,后处理更耗时且准确性更低。

将对象簇拆分为单独的对象实例
识别集群内的单个对象:
- 基于分水岭的分割:返回包含单个草莓检测的感兴趣区域>白色像素合并在一起>应对颜色变换的负面影响>所有检测的中心用作基于分水岭的分割的初始化位置>每个区域的边界由合并的二值图像定义,精确定位可能有草莓像素的区域> 通过合并的二值图像定义每个区域的边界,精确定位可能有草莓像素的区域。
- 基于立体三角测量的分割:避免分水岭分割的严格边界>给定的 2D 图像中每个草莓的位置都是已知的>高斯滤波器的差异
参考
[1] B. Zheng、G. Sun、Z. Meng 和 R. Nan,“基于立体相机和关键点检测的蔬菜尺寸测量”,《传感器》,第 22 卷,第 4 期,第 4 号,2022 年 1 月,DOI:10.3390/s22041617。
[2] U. Rahamathunnisa、MK Nallakaruppan、A. Smith 和 S. Kumar KS,“使用 K 均值聚类和 Svm 检测蔬菜病害”,2020 年第 6 届先进计算和通信系统国际会议 (ICACCS),2020 年 3 月,第 1308-1311 页。DOI:10.1109/ICACCS48705.2020.9074434。
[3] B. Zhang等人,“计算机视觉在水果和蔬菜外部质量检测中的原理、发展和应用:综述”,《国际食品研究》,第 62 卷,第 326-343 页,2014 年 8 月,DOI:10.1016/j.foodres.2014.03.012。
[4] A. Bhargava 和 A. Bansal,“使用计算机视觉进行水果和蔬菜品质评估:综述”,《沙特国王大学计算机与信息科学杂志》,第 33 卷,第 3 期,第 243-257 页,2021 年 3 月,DOI:10.1016/j.jksuci.2018.06.002。
[5] BS Bennedsen、DL Peterson、A. Tabbn,“使用主成分分析和人工神经网络识别苹果表面缺陷”,美国农业和生物工程师协会,第 50 卷,第 6 期,第 2257-2265 页,2007 年,ISSN 0001-2351链接
[6] A. Petsiuk、H. Singh、H. Dadhwal 和 JM Pearce,“增材制造中的合成到真实复合语义分割”。arXiv,2022 年 10 月 13 日。DOI:10.48550/arXiv.2210.07466。
[7] U. Afzaal、B. Bhattarai、YR Pandeya 和 J. Lee,“基于 Mask R-CNN 的草莓疾病实例分割模型”,《传感器》,第 21 卷,第 19 期,第 19 号,2021 年 1 月,DOI:10.3390/s21196565。
[8] MK Prem Kumar 和 A. Parkavi,“使用图像处理技术和机器学习对水果和蔬菜进行质量分级:综述”,《通信系统和网络的发展》,新加坡,2020 年,第 477-486 页。DOI:10.1007/978-981-15-3992-3_40.8]
[9] SR Dubey 和 AS Jalal,“图像处理在水果和蔬菜分析中的应用:综述”,《智能系统杂志》 ,第 24 卷,第 4 期,第 405-424 页,2015 年 12 月,DOI:10.1515 / jisys-2014-0079。
[10] S. Puttemans、Y. Vanbrabant、L. Tits 和 T. Goedemé,“自动视觉水果检测用于收获评估和机器人采摘”,2016 年第六届国际图像处理理论、工具和应用会议 (IPTA),2016 年 12 月,第 1-6 页。DOI:10.1109/IPTA.2016.7820996.0] DOI:10.1109/IPTA.2016.7820996
[11] D. Stajnko 和 Z. Cˇmelik。通过图像分析对苹果果实生长进行建模。农业科学概论,70(2):59–64, 2005。
待完成:
[] E. Saldaña、R. Siche、M. Luján 和 R. Quevedo,“评论:计算机视觉应用于水果和蔬菜的检测和质量控制”,Braz. J. Food Technol.,第 16 卷,第 254-272 页,2013 年 12 月,DOI:10.1590/S1981-67232013005000031。
[] M. Khojastehnezhad、M. Omid、A. Tabatabaeefar,“基于颜色和大小的柠檬分类系统的开发”《非洲植物科学杂志》第 4(4) 卷,第 122-127 页,2010 年 4 月,链接
[] Y. Song, C. Glasbey 等。通过多幅图像自动识别和计数水果。生物系统工程,118:203–215,2014 年。
[] S. Puttemans 和 T. Goedem´e。兰花的视觉检测和物种分类。在 MVA,第 505-509 页。IEEE,2015 年。