
ALL-SAFE/Validation Evidence
Our team understands that a platform is only as good as the evidence supporting it. Therefore, ALL-SAFE has made great efforts to evaluate the efficacy, feasibility, usability, and clinical relevance of our platform. We want to make sure that our efforts are actually improving laparoscopic surgery education in our target sites.
We have conducted several rigorous scientific studies to evaluate the validity evidence of our platform and its assessment measurement. Our key findings can be found below.
Key Findings
[edit | edit source]Through our feasibility studies, we have learned that our ALL-SAFE platform works in low-resource settings with limited resources and internet bandwidth. We are working to improve this accessibility continuously through innovative measures and iterative adjustments.
Learners who have successfully completed our first two modules demonstrated statistically significant increases in knowledge assessment scores.
Evidence suggests our VOP can be used to distinguish novice from expert surgeons based on the psychomotor skills demonstrated on video.
Our findings indicate peer reviewers' VOP ratings correlate with experts' ratings. Given that the module is not dependent on expert reviewers, we expect improved feedback times and increased assessment reliability. Additionally, we anticipate added benefits for the participants in their dual roles as a learner and evaluator.
Preliminary evidence indicates a targeted sample of learners from our Mbingo site who successfully completed the appendectomy module were able to translate learned operative skills to laparoscopic appendectomies in real patients with appropriate supervision. Ratings captured in the simulated environment were comparable to those captured in the live environment.
Detailed validation data from Platform feasibility, Module 1 (Ectopic Pregnancy), Module 2 (Appendectomy) can be found below.
Summarized Evaluation Protocols
[edit | edit source] |
 |
|---|
Testing Ease of Build and Usability of the Box Trainer
[edit | edit source]ALL-SAFE conducted a study to assess the ease of build and usability for both the box trainer and ectopic sim which guided our modeling. Find the results (PDF) by clicking on the picture below.

Cognitive / Procedure Components Validation
[edit | edit source]Ectopic Pregnancy Module
[edit | edit source]Methods: 20 participants from 3 sites completed the web-based cognitive modules (pre-test, case scenario, and post-test). Participants included 2 Ob/Gyn attendings, 2 General Surgery attendings, 3 first-year residents, 1 second-year resident, 1 third-year resident, and 7 medical students. All participating sites were represented (Mbingo, n=3; Soddo, n=6; Southern Illinois University School of Medicine, n=3; University of Michigan School of Medicine, n=8).
The identical (but shuffled in presentation) 10-item pre- and post-module quizzes were scored dichotomously (1=correct, 0=incorrect) and summed for each participant. Pre- and post-module summed scores were compared using paired student-test with SPSS Statistics for Windows v.25 (IBM, Armonk, NY) while differences in scores across participants' experience and site were analyzed using a many-facet Rasch model using Facets software v. 3.50 (Winsteps.com, Beaverton, OR) following anchoring on subjects to accommodate for nested design across sites.
Results: We did see a sig difference across Pre/Post summed scores, with a positive trend observed between higher scores and increasing experience. The two most difficult questions, as determined by item discrimination, were rewritten to improve readability and cognitive flow for our non-native English speaker audience.

Acute Appendicitis Module
[edit | edit source]Methods. 24 participants from 4 sites completed the web-based module. Participants included 15 novice, 6 intermediate, and 3 expert participants. All participating sites were represented (Mbingo, n=9; MRS, n=1; Soddo, n=6; UM, n=8).
The identical (but shuffled in presentation) 10-item pre- and post-module quizzes were scored dichotomously (1=correct, 0=incorrect) and summed for each participant, with a maximum score of 10. Pre- and post-module summed scores were compared using paired student-test, while differences between novice, intermediate, and expert participants was tested using one-way ANOVA, both with SPSS Statistics for Windows v.25 (IBM, Armonk, NY) Item-level analyses were performed using a many-facet Rasch model using Facets software v. 3.50 (Winsteps.com, Beaverton, OR) following anchoring on subjects to accommodate for nested design across sites.
Results: Cognitive test effectively discriminated between novice, intermediate, and expert participants, and demonstrated benefit to novice and intermediate participants with statistically significant score improvements for novice and intermediate groups, p≤ .032. Item discrimination analysis suggests review/potential modification of 2 questions (Qs 3/5) to ensure questions target is indeed covered within content, and language is clear. Evidence suggests Intermediate participants came in with set knowledge (Pre-test means for Qs 1,4, 5, and 6 = 1.0, SD=.00), which is expected. Given that mean post-test scores are still low (M=7.47, SD = 1.58) for novices, we kept our current model of requiring review of content until they achieve mastery (100%), after ensuring content indeed aligns with questions 3 and 5.

Psychomotor / Simulation Components Validation: Validation Evidence for our VOP
[edit | edit source]Ectopic Pregnancy Module
[edit | edit source]In our pilot study, we observed that there is no significant difference in assessments performed by learner peers and experts when the Verification of Proficiency was utilized. This allows for unlimited scalability without reliance on expert assessment.

Acute Appendicitis Module
Similar to the ectopic pregnancy module, comparison of novice /intermediate/ expert performance ratings at the VOP Checklist item-level was not helpful to discriminate performance levels, but was helpful at the summed total of the checklist (SUMMED) level (p=.005). Overall, checklist scores were able to discriminate across 3 levels of ability; Competent (M=2.0), Borderline (M=1.8), Not Competent (M=1.4), Χ2 (85)= 32.3, p=.001, suggesting that these three response options could adequately discriminate subjects.
All 5 Global VOP domains were able discriminate across the 3 (novice, intermediate, and expert) performance levels, p= |.001, .002|. The Global Summed, Total Sum, and Final Rating were all able to discriminate across these 3 levels of performance, p<.001 for all. Many-facet Rasch Model analysis indicated statistical scoring differences across Final Rating (e.g. Competent, Borderline, and Not Competent); Competent (M=3.8), Borderline (M=2.7), Not Competent (M=1.8), Χ2 (85)= 243.3, p=.001, suggesting that Global scoring could adequately discriminate subjects across these three response options.
Inter-rater reliability estimated by averaged two-way mixed Intraclass correlation, indicated mixed reliability of Global ratings, ranging from .45 (poor) to .83 (moderate-high). Variability in reliability estimates could be caused by small sample size combined with need for supportive materials.

Preliminary Internal Evaluation of ALL-SAFE Program VOP Performance Measures
[edit | edit source]Combined as a single program. Overall, the MFRM supported previous findings from classical test analyses. Findings indicated:
- ALL-SAFE training performance measures were able to discriminate high vs. low performances for resident participants
- RASCH Analysis suggested no performance-based biases across sites
- Indicated no rating bias across trainee and attending
- Indicated that participants’ scores improved over time and with modules

Pilot Testing / Evaluation
[edit | edit source]Pilot testing has led to improvements in all aspects of the module.
All components of the full surgical modules, including the cognitive case scenario and the psychomotor skills components, have undergone multiple rounds of testing, improvements based on pilot feedback, and re-testing at all of our sites. Following is a list of notable improvements to both components:
All components of the module were tested for reproducibility. Participants from all of our sites completed both the cognitive and the psychomotor aspects of the modules. For the cognitive portion, we evaluated the directions for use and access and usability of our web platform for the case scenario. Regarding reproducibility of the simulator, we had participants from all our sites use the instructions to construct the box trainer and simulation, rating the clarity of the instructions, ease of the construction, and time to build. The instructions were modified after each participating site confirmed clarity and ease of use. We additionally evaluated the sites' internet connectivity and ease of access to the web-based program to ensure adequate access to the program, and technical improvements were made. Volunteers successfully performed all components of the psychomotor testing including video upload, video review, and checklist verification. Feedback for improvement was incorporated into later iterations.
Following is a list of notable improvements to both components:
Examples of Implemented Feedback
- Rewording of various pre-test and post-test questions as well as elements of case scenario to improve clarity of comprehension at pilot sites
- Improvement in dimensions of box trainer to better emulate pelvic cavity and realistic trocar positions for this procedure
- Improvements to ectopic model (fixation of model to table, use of a white paper background to emphasize contrast for visualization)
- Establishment of video connection between laparoscope/cell phone and monitor/computer through EpocCam and other methods rather than Zoom, Skype, Facetime, or Facebook messenger which had prohibitive data transmission speeds at the pilot sites or were not readily available.
- Adjustment of recipe for playdough to simulate ectopic contents to improve realistic tactility, ectopic evacuation, and ease of use with laparoscopic graspers.
- Technical adjustments to platform including video optimization prior to video upload to accommodate slower data speeds
- Availability of all materials in PDF form to accommodate offline use and slower data speeds
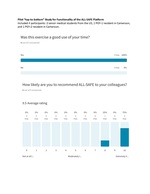
Functionality Pilot 2021
[edit | edit source]4 learners from both African and US sites tested out our ectopic pregnancy platform "top-to-bottom." They provided feedback on functionality of the site. To see a report of this feedback and the items we subsequently changed/adapted, please click below.
Evidence of Clinical Translation
[edit | edit source]Acute Appendicitis Module
[edit | edit source]For more details on this study, please visit ALL-SAFE/Clinical Translation

| Authors | ALL SAFE |
|---|---|
| License | CC-BY-SA-4.0 |
| Organizations | University of Michigan, Soddo Christian Hospital (Ethiopia), Mbingo Hospital (Cameroon), Kijabe Hospital (Kenya), Southern Illinois University |
| Cite as | ALL SAFE (2022–2025). "ALL-SAFE/Validation Evidence". Appropedia. Retrieved July 12, 2026. |